本文在博客的帮助下完成,因其文章过于久远,不具备时效性,部分代码片段早已更新修改
本文照其思路对go语言部分源码进行解析 截图与代码分析均为Go 1.23版本
编译原理
基础知识
数据结构
数组
数组是由相同类型元素的集合组成的数据结构,计算机会为数组分配一块连续的内存来保存其中的元素,我们可以利用数组中元素的索引快速访问特定元素,常见的数组大多都是一维的线性数组,而多维数组在数值和图形计算领域却有比较常见的应用
[10]int
[200]interface{}
数组可以这样表示
go语言数组在初始化之后大小就无法改变了,大小不同的数组也不是同一类型
在go的源码cmd/compile/internal/types.NewArray里
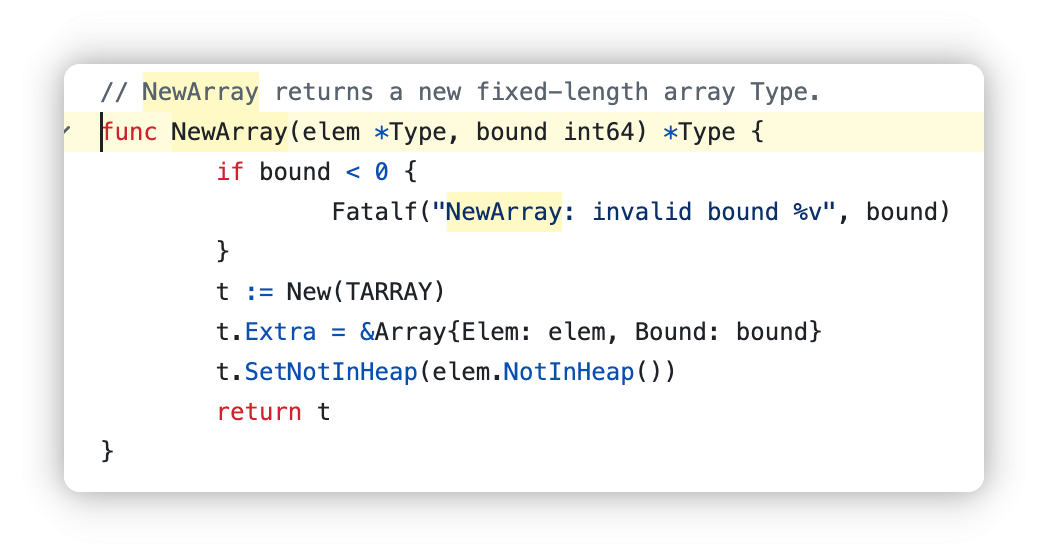 我们可以看到,两个参数,一个是type,另一个是bound
我们可以看到,两个参数,一个是type,另一个是bound
初始化
arr := [3]int{1,2,3}
arr := [...]int{1,2,3}
这两者初始化都是对的,在运行时期得到的结果完全一致,后者在编译时就会变成前者
前者在类型检查的时候会被提取出来用上述截图部分代码进行创建数组
后者会在cmd/compile/internal/gc.typecheckcomplit对大小进行推导

跟进,发现
会遍历得到length

如果大于四个元素,会将其静态初始化
小于四个会进行优化
var arr [3]int
arr[0] = 1
arr[1] = 2
arr[2] = 3
如果是大于四个执行以下操作
var arr [5]int
statictmp_0[0] = 1
statictmp_0[1] = 2
statictmp_0[2] = 3
statictmp_0[3] = 4
statictmp_0[4] = 5
arr = statictmp_0
怎么理解区别呢,静态数据在编译期间确定并存储在二进制文件中,如.data段
运行时数据在程序运行时分配内存,并赋值初始化
大于四个时,数据被存在二进制文件里
.rodata:
statictmp_0 = [1, 2, 3, 4, 5]
在运行时仅进行拷贝操作
arr = statictmp_0
小元素直接分布在栈上
越界检查
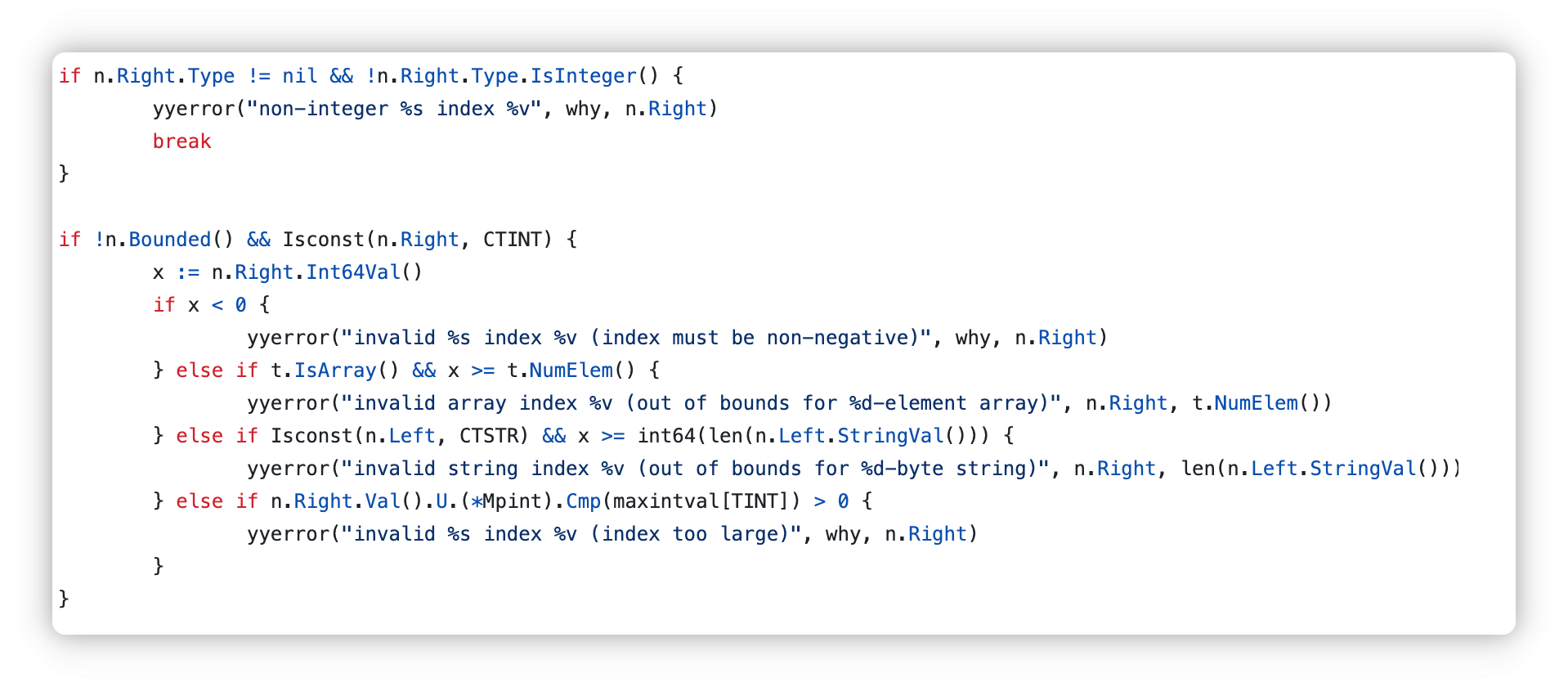
Left是被索引的对象,Right是索引表达式
我们可以很清楚的看到,这里检查了右侧,即index的值是否是整数,是否为负数,是否越界
这里还检查了索引不能超过int64位的值,但是能开辟64位值大小空间的数组的机器,内存也是非常恐怖了(
拷贝
默认值拷贝
切片
// SliceHeader is the runtime representation of a slice.
// It cannot be used safely or portably and its representation may
// change in a later release.
// Moreover, the Data field is not sufficient to guarantee the data
// it references will not be garbage collected, so programs must keep
// a separate, correctly typed pointer to the underlying data.
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
运行时的切片定义如上
从结构体定义的看出,切片实际上就是一段连续的内存空间,加上长度和容量标识
初始化
s := arr[:2]
s := []int{1,2,3}
s := make([]int, 10)
当初始化切片容量特别大的时候,或者发生了逃逸,会在堆上初始化
ps:逃逸是指变量从栈内存转移到堆内存的过程,当编译器无法确定变量的生命周期是否在当前函数内完全结束的时候,变量会逃逸到堆,确保函数返回后依旧有效
栈上初始化是自动管理,堆上需要GC管理
package main
func createSlice() []int {
return make([]int, 3) // 切片逃逸
}
func main() {
_ = make([]int, 3, 4) // 切片在栈上分配
_ = createSlice()
_ = make([]int, 1000000)
}
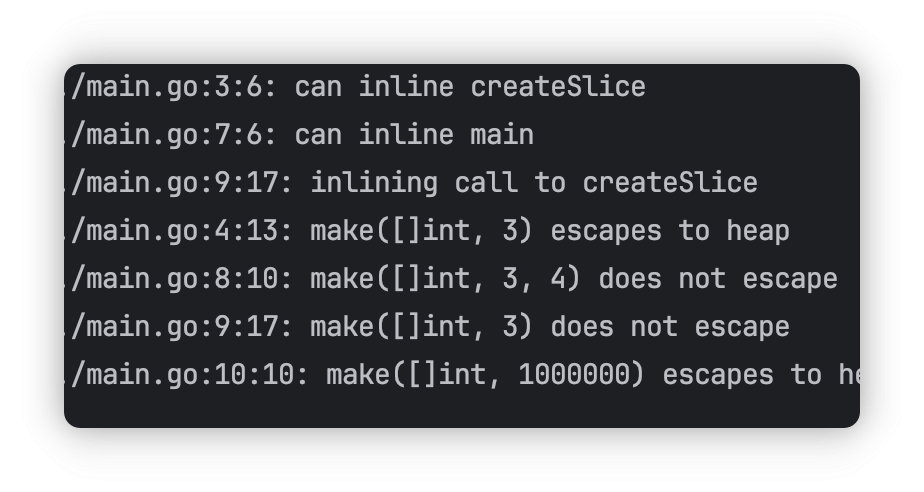
可以看到大数组确实发生了逃逸,小的没有(这里同时还内联展开了)
return 切片的时候也会发生逃逸
切片容量计算方式是:
内存空间 = 元素大小 × 切片容量
访问元素
切片的len和cap在编译器看来是OLEN和OCAP操作
扩容
扩容也是面试中常考的部分
slice是如何扩容的?
在此之前 我们先翻阅追加的过程
Go 1.18后
func (s *state) append(n *Node, inplace bool) *ssa.Value {
// If inplace is false, process as expression "append(s, e1, e2, e3)":
//
// ptr, len, cap := s
// newlen := len + 3
// if newlen > cap {
// ptr, len, cap = growslice(s, newlen)
// newlen = len + 3 // recalculate to avoid a spill
// }
// // with write barriers, if needed:
// *(ptr+len) = e1
// *(ptr+len+1) = e2
// *(ptr+len+2) = e3
// return makeslice(ptr, newlen, cap)
//
//
// If inplace is true, process as statement "s = append(s, e1, e2, e3)":
//
// a := &s
// ptr, len, cap := s
// newlen := len + 3
// if uint(newlen) > uint(cap) {
// newptr, len, newcap = growslice(ptr, len, cap, newlen)
// vardef(a) // if necessary, advise liveness we are writing a new a
// *a.cap = newcap // write before ptr to avoid a spill
// *a.ptr = newptr // with write barrier
// }
// newlen = len + 3 // recalculate to avoid a spill
// *a.len = newlen
// // with write barriers, if needed:
// *(ptr+len) = e1
// *(ptr+len+1) = e2
// *(ptr+len+2) = e3
et := n.Type.Elem()
pt := types.NewPtr(et)
// Evaluate slice
sn := n.List.First() // the slice node is the first in the list
var slice, addr *ssa.Value
if inplace {
addr = s.addr(sn)
slice = s.load(n.Type, addr)
} else {
slice = s.expr(sn)
}
// Allocate new blocks
grow := s.f.NewBlock(ssa.BlockPlain)
assign := s.f.NewBlock(ssa.BlockPlain)
// Decide if we need to grow
nargs := int64(n.List.Len() - 1)
p := s.newValue1(ssa.OpSlicePtr, pt, slice)
l := s.newValue1(ssa.OpSliceLen, types.Types[TINT], slice)
c := s.newValue1(ssa.OpSliceCap, types.Types[TINT], slice)
nl := s.newValue2(s.ssaOp(OADD, types.Types[TINT]), types.Types[TINT], l, s.constInt(types.Types[TINT], nargs))
cmp := s.newValue2(s.ssaOp(OLT, types.Types[TUINT]), types.Types[TBOOL], c, nl)
s.vars[&ptrVar] = p
if !inplace {
s.vars[&newlenVar] = nl
s.vars[&capVar] = c
} else {
s.vars[&lenVar] = l
}
b := s.endBlock()
b.Kind = ssa.BlockIf
b.Likely = ssa.BranchUnlikely
b.SetControl(cmp)
b.AddEdgeTo(grow)
b.AddEdgeTo(assign)
// Call growslice
s.startBlock(grow)
taddr := s.expr(n.Left)
r := s.rtcall(growslice, true, []*types.Type{pt, types.Types[TINT], types.Types[TINT]}, taddr, p, l, c, nl)
if inplace {
if sn.Op == ONAME && sn.Class() != PEXTERN {
// Tell liveness we're about to build a new slice
s.vars[&memVar] = s.newValue1A(ssa.OpVarDef, types.TypeMem, sn, s.mem())
}
capaddr := s.newValue1I(ssa.OpOffPtr, s.f.Config.Types.IntPtr, sliceCapOffset, addr)
s.store(types.Types[TINT], capaddr, r[2])
s.store(pt, addr, r[0])
// load the value we just stored to avoid having to spill it
s.vars[&ptrVar] = s.load(pt, addr)
s.vars[&lenVar] = r[1] // avoid a spill in the fast path
} else {
s.vars[&ptrVar] = r[0]
s.vars[&newlenVar] = s.newValue2(s.ssaOp(OADD, types.Types[TINT]), types.Types[TINT], r[1], s.constInt(types.Types[TINT], nargs))
s.vars[&capVar] = r[2]
}
b = s.endBlock()
b.AddEdgeTo(assign)
// assign new elements to slots
s.startBlock(assign)
if inplace {
l = s.variable(&lenVar, types.Types[TINT]) // generates phi for len
nl = s.newValue2(s.ssaOp(OADD, types.Types[TINT]), types.Types[TINT], l, s.constInt(types.Types[TINT], nargs))
lenaddr := s.newValue1I(ssa.OpOffPtr, s.f.Config.Types.IntPtr, sliceLenOffset, addr)
s.store(types.Types[TINT], lenaddr, nl)
}
// Evaluate args
type argRec struct {
// if store is true, we're appending the value v. If false, we're appending the
// value at *v.
v *ssa.Value
store bool
}
args := make([]argRec, 0, nargs)
for _, n := range n.List.Slice()[1:] {
if canSSAType(n.Type) {
args = append(args, argRec{v: s.expr(n), store: true})
} else {
v := s.addr(n)
args = append(args, argRec{v: v})
}
}
p = s.variable(&ptrVar, pt) // generates phi for ptr
if !inplace {
nl = s.variable(&newlenVar, types.Types[TINT]) // generates phi for nl
c = s.variable(&capVar, types.Types[TINT]) // generates phi for cap
}
p2 := s.newValue2(ssa.OpPtrIndex, pt, p, l)
for i, arg := range args {
addr := s.newValue2(ssa.OpPtrIndex, pt, p2, s.constInt(types.Types[TINT], int64(i)))
if arg.store {
s.storeType(et, addr, arg.v, 0, true)
} else {
s.move(et, addr, arg.v)
}
}
delete(s.vars, &ptrVar)
if inplace {
delete(s.vars, &lenVar)
return nil
}
delete(s.vars, &newlenVar)
delete(s.vars, &capVar)
// make result
return s.newValue3(ssa.OpSliceMake, n.Type, p, nl, c)
}
其中评估切片部分
sn := n.List.First() // 获取切片
var slice, addr *ssa.Value
if inplace {
addr = s.addr(sn) // 如果是赋值语句,获取切片的地址
slice = s.load(n.Type, addr) // 加载切片
} else {
slice = s.expr(sn) // 如果是表达式,直接获取切片值
}
然后是判断是否需要扩容
// Decide if we need to grow
nargs := int64(n.List.Len() - 1)
p := s.newValue1(ssa.OpSlicePtr, pt, slice)
l := s.newValue1(ssa.OpSliceLen, types.Types[TINT], slice)
c := s.newValue1(ssa.OpSliceCap, types.Types[TINT], slice)
nl := s.newValue2(s.ssaOp(OADD, types.Types[TINT]), types.Types[TINT], l, s.constInt(types.Types[TINT], nargs))
cmp := s.newValue2(s.ssaOp(OLT, types.Types[TUINT]), types.Types[TBOOL], c, nl)
如果需要扩容,就会触发growslice
// Call growslice
s.startBlock(grow)
taddr := s.expr(n.Left)
r := s.rtcall(growslice, true, []*types.Type{pt, types.Types[TINT], types.Types[TINT]}, taddr, p, l, c, nl)
if inplace {
if sn.Op == ONAME && sn.Class() != PEXTERN {
// Tell liveness we're about to build a new slice
s.vars[&memVar] = s.newValue1A(ssa.OpVarDef, types.TypeMem, sn, s.mem())
}
capaddr := s.newValue1I(ssa.OpOffPtr, s.f.Config.Types.IntPtr, sliceCapOffset, addr)
s.store(types.Types[TINT], capaddr, r[2])
s.store(pt, addr, r[0])
// load the value we just stored to avoid having to spill it
s.vars[&ptrVar] = s.load(pt, addr)
s.vars[&lenVar] = r[1] // avoid a spill in the fast path
} else {
s.vars[&ptrVar] = r[0]
s.vars[&newlenVar] = s.newValue2(s.ssaOp(OADD, types.Types[TINT]), types.Types[TINT], r[1], s.constInt(types.Types[TINT], nargs))
s.vars[&capVar] = r[2]
}
b = s.endBlock()
b.AddEdgeTo(assign)
观察growslice,我们可以发现
r := s.rtcall(growslice, true, []*types.Type{pt, types.Types[TINT], types.Types[TINT]}, taddr, p, l, c, nl)
核心语句就是这个
最后写入新元素
p2 := s.newValue2(ssa.OpPtrIndex, pt, p, l) // 计算新元素的起始地址
for i, arg := range args {
addr := s.newValue2(ssa.OpPtrIndex, pt, p2, s.constInt(types.Types[TINT], int64(i))) // 每个元素的地址
if arg.store {
s.storeType(et, addr, arg.v, 0, true) // 存储值
} else {
s.move(et, addr, arg.v) // 移动值
}
}sho
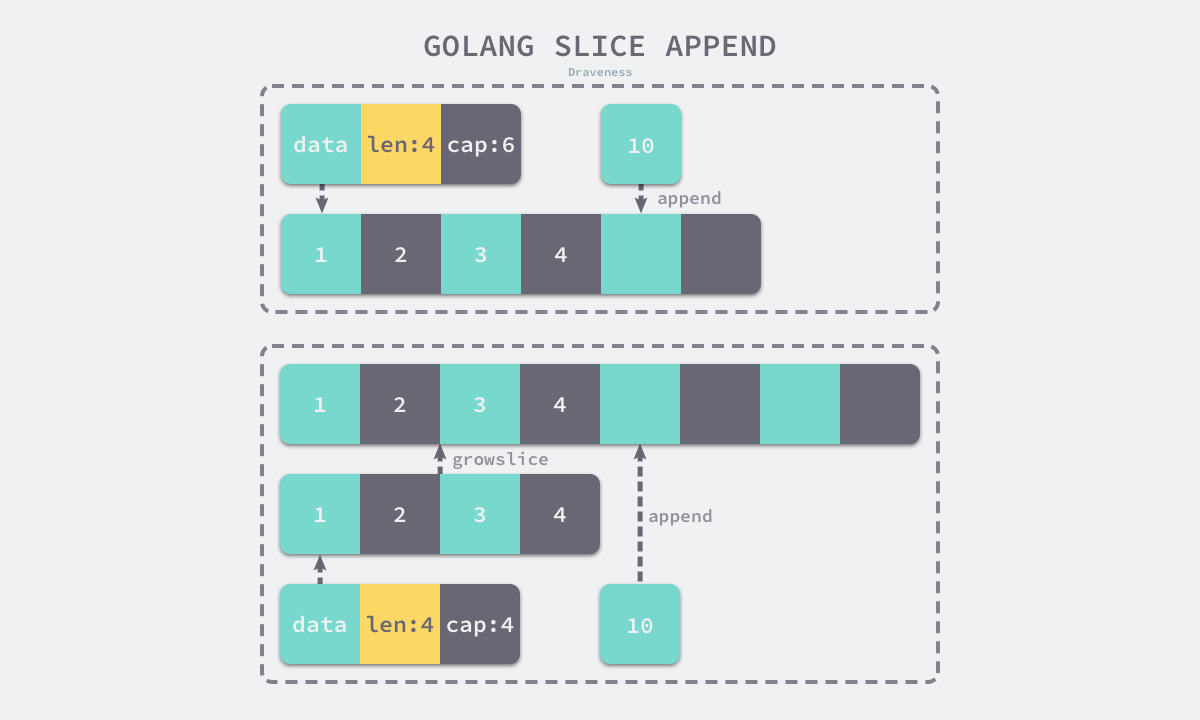
博主画的图很好理解,直接拿来用了
回到上面的问题,slice是怎么扩容的?扩容多少倍的呢?
前面已经展示了会调用call触发growslice,我们去查看这个函数,可以发现

func growslice(
oldPtr unsafe.Pointer, // 旧数组的指针
newLen int, // 新切片的长度(旧长度 + 新增元素数)
oldCap int, // 当前切片的容量
num int, // 新增的元素数
et *_type, // 元素类型信息
) slice
返回的是一个slice
在检查合法性之后,有一行关键代码

这里就是新的容量,我们接着跟进可以发现
func nextslicecap(newLen, oldCap int) int {
newcap := oldCap
doublecap := newcap + newcap
if newLen > doublecap {
return newLen
}
const threshold = 256
if oldCap < threshold {
return doublecap
}
for {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) >> 2
// We need to check `newcap >= newLen` and whether `newcap` overflowed.
// newLen is guaranteed to be larger than zero, hence
// when newcap overflows then `uint(newcap) > uint(newLen)`.
// This allows to check for both with the same comparison.
if uint(newcap) >= uint(newLen) {
break
}
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
return newLen
}
return newcap
}
初始化一个newcap,令doublecap 等于双倍的newcap
如果扩容两倍还不够,直接返回newLen
如果 oldCap小于256,直接返回两倍扩容
接着for循环内的注释说明了一切:从小切片增长2倍过渡到大型切片增长1.25倍。此公式在两者之间提供了一个相对平滑的过渡。
newcap += (newcap + 3*threshold) >> 2
这个式子计算方式,当cap无限大的时候,256可以忽略,newcap等于1.25cap
当cap为256的时候,newcap等于2倍的newcap
我们可以在本地测试
func main() {
ocap := 256
s := make([]int, ocap)
for i := 0; i < ocap; i++ {
s[i] = i
}
fmt.Println(len(s), cap(s))
s = append(s, 1)
fmt.Println(len(s), cap(s))
newcap := ocap
newcap += (newcap + 3*256) >> 2
fmt.Printf("newcap is %d", newcap)
}
但是我们运行的时候发现
在设置ocap为256时,扩容大小确实和我们计算的保持一致
256 256
257 512
newcap is 512
但是如果初始为257,扩容大小和我们计算的就有出入了
257 257
258 608
newcap is 513
这里还需要进行内存对齐,详情请看下文内存对齐部分
Go 1.18前
当新切片需要的容量cap大于两倍扩容的容量,则直接按照新切片需要的容量扩容
当原 slice 容量 < 1024 的时候,新 slice 容量变成原来的 2 倍
当原 slice 容量 > 1024,进入一个循环,每次容量变成原来的1.25倍,直到大于期望容量
内存对齐
有时候会发现,并不严格按照公式进行运算
s := make([]int, ocap)
for i := 0; i < ocap; i++ {
s[i] = i
}
fmt.Println(len(s), cap(s))
s = append(s, 1, 2, 3, 4)
fmt.Println(len(s), cap(s))
1 1
5 6
新的cap变成了6而不是5
存在的内存对齐
var overflow bool
var lenmem, newlenmem, capmem uintptr
// Specialize for common values of et.Size.
// For 1 we don't need any division/multiplication.
// For goarch.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
noscan := !et.Pointers()
switch {
case et.Size_ == 1:
lenmem = uintptr(oldLen)
newlenmem = uintptr(newLen)
capmem = roundupsize(uintptr(newcap), noscan)
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.Size_ == goarch.PtrSize:
lenmem = uintptr(oldLen) * goarch.PtrSize
newlenmem = uintptr(newLen) * goarch.PtrSize
capmem = roundupsize(uintptr(newcap)*goarch.PtrSize, noscan)
overflow = uintptr(newcap) > maxAlloc/goarch.PtrSize
newcap = int(capmem / goarch.PtrSize)
case isPowerOfTwo(et.Size_):
var shift uintptr
if goarch.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.TrailingZeros64(uint64(et.Size_))) & 63
} else {
shift = uintptr(sys.TrailingZeros32(uint32(et.Size_))) & 31
}
lenmem = uintptr(oldLen) << shift
newlenmem = uintptr(newLen) << shift
capmem = roundupsize(uintptr(newcap)<<shift, noscan)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
capmem = uintptr(newcap) << shift
default:
lenmem = uintptr(oldLen) * et.Size_
newlenmem = uintptr(newLen) * et.Size_
capmem, overflow = math.MulUintptr(et.Size_, uintptr(newcap))
capmem = roundupsize(capmem, noscan)
newcap = int(capmem / et.Size_)
capmem = uintptr(newcap) * et.Size_
}
这是因为8字节一位的话,5 个元素40字节,小于48 向上取整48
列表为
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 24, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
我们回过头去看看刚刚的257个cap全部占满,当我们append的时候本应扩容 (257 + 3 * 256) >> 2
实际我们扩容后确得到了608
计算一下,本应该分配513个元素,513 x 8 = 4104
查表,找到4104后的第一个元素4864
4864/8正好为608
按照这个思路,
我们把cap改成444,猜测一下,新扩容的大小应该是
444 + 3 * 256 >> 2 = 303
747 * 8 = 5796
我们查表发现5796的下一个元素是6144,除以8得到768
运行代码,验证结果

结果正确
拷贝
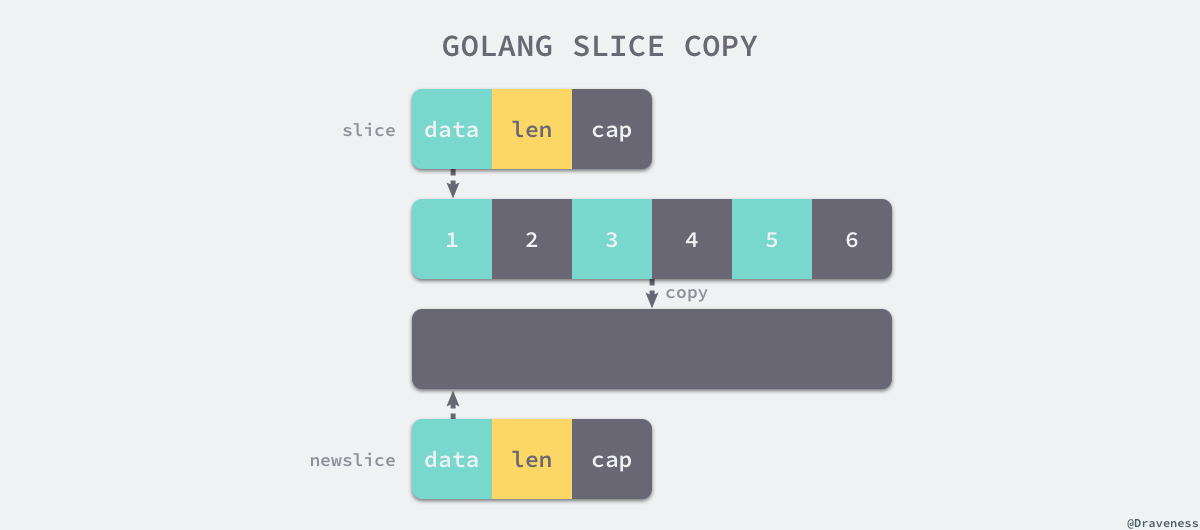
拷贝内存
hash表
hash表的实现有两个关键
- hash函数
- hash冲突 具体概念这里就不细说了,大概都知道
完美的hash函数需要让结果分布均匀,尽量避免hash冲突
冲突解决
为了节省内存和提高效率,在hash表计算存储位置的时候,不会直接使用整个hash,而是使用hash值的一部分,但是这样也就造成了更多可能的hash碰撞
- 开放寻址
- 拉链法
开放寻址
这种方法的核心思想是依次探测和比较数组中的元素以判断目标键值对是否存在于哈希表中,如果我们使用开放寻址法来实现哈希表,那么实现哈希表底层的数据结构就是数组,不过因为数组的长度有限,向哈希表写入 (author, draven) 这个键值对时会从如下的索引开始遍历
index := hash("author") % array.len
当我们向当前哈希表写入新的数据时,如果发生了冲突,就会将键值对写入到下一个索引不为空的位置
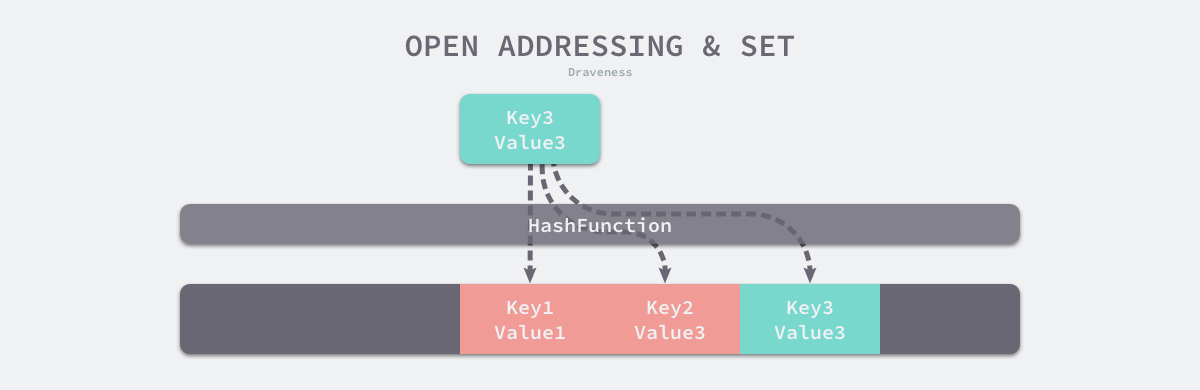
写入key3时,发现对应hash位置写入k1,接着后找,发现写入k2,接着后找,写入k3的位置
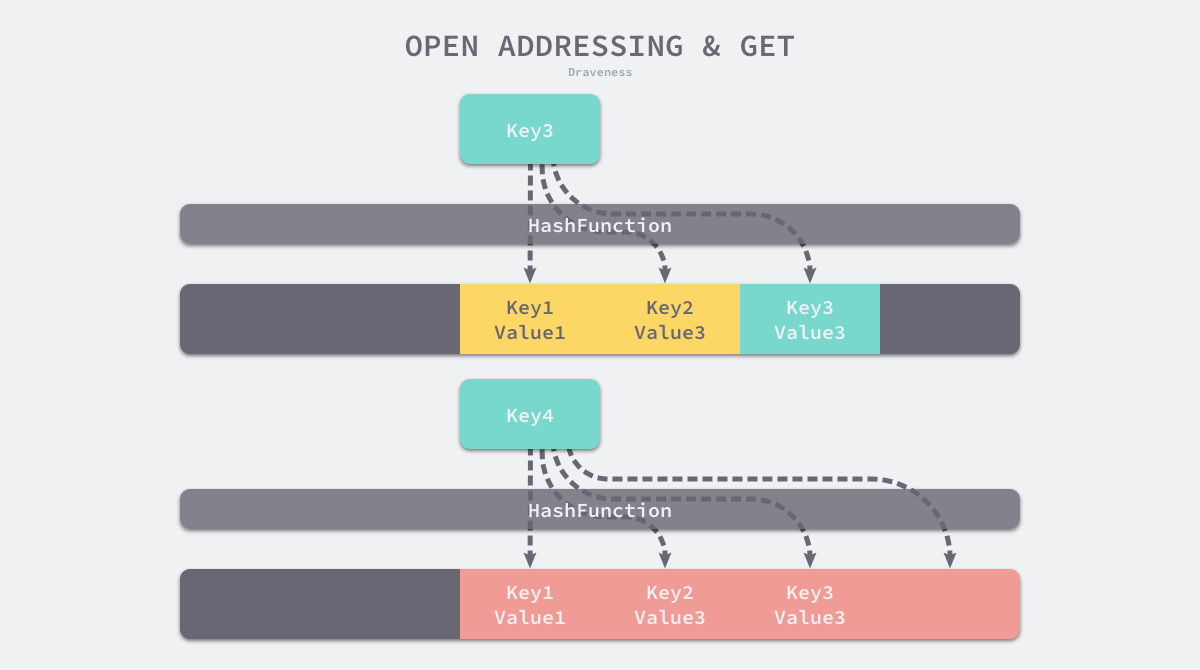

拉链法
大多数的编程语言都用拉链法实现哈希表,它的实现比较开放地址法稍微复杂一些,但是平均查找的长度也比较短,各个用于存储节点的内存都是动态申请的,可以节省比较多的存储空间
拉链法会使用链表数组作为哈希底层的数据结构,我们可以将它看成可以扩展的二维数组
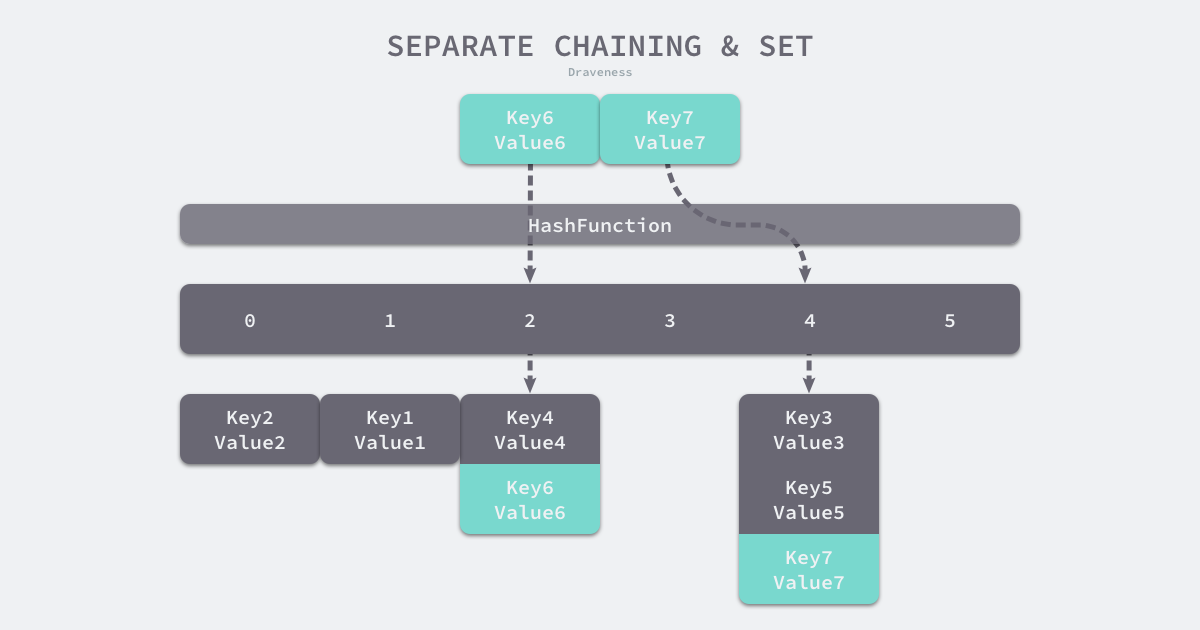
一些编程语言会在其中引入红黑树以优化性能
开始和开放寻址一样,都是对key进行hash后选择一个位置
不过在拉链法里,寻找的是一个桶
在这期间如果发生了hash冲突,就会在链表追加新的元素,当查询的时候,直接遍历链表寻找就行了
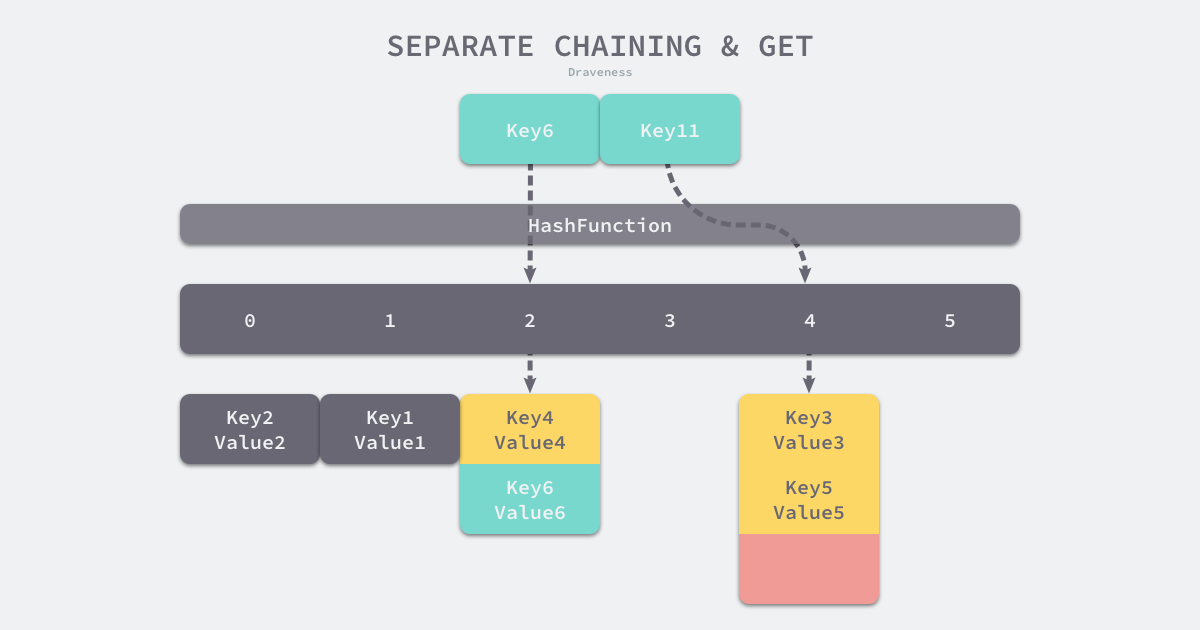
这其中有一个概念
$$装载因子 := 元素数量 \div 桶数量$$
装载因子越大,hash读写性能越差
go的map实现
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
count表示当前哈希表中的元素数量;B表示当前哈希表持有的buckets数量,但是因为哈希表中桶的数量都 2 的次方数,所以该字段会存储对数,也就是len(buckets) == 2^Bhash0是哈希的种子,它能为哈希函数的结果引入随机性,这个值在创建哈希表时确定,并在调用哈希函数时作为参数传入;oldbuckets是哈希在扩容时用于保存之前buckets的字段,它的大小是当前buckets的一半;
为什么存储桶是2的次方呢
分析一下
hash % (2 * n)
这是hash函数的话
hash & (2 * n - 1)
等价于上面这个位运算,所以能加速运算
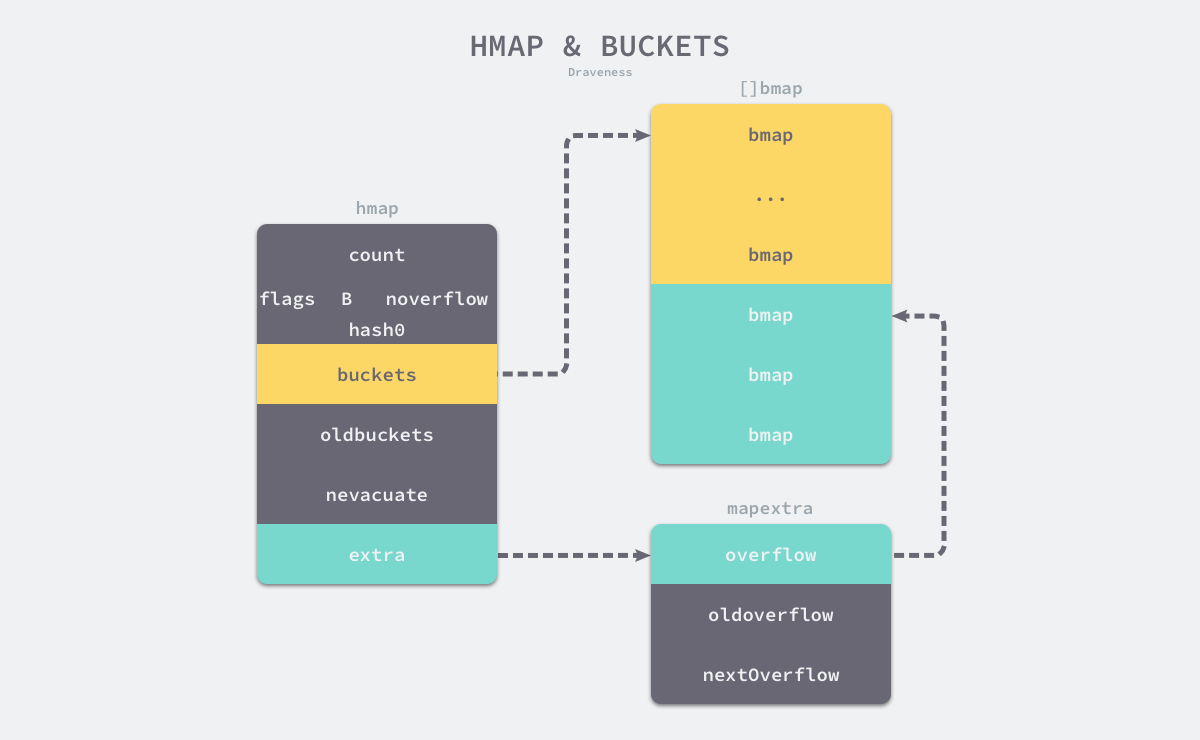
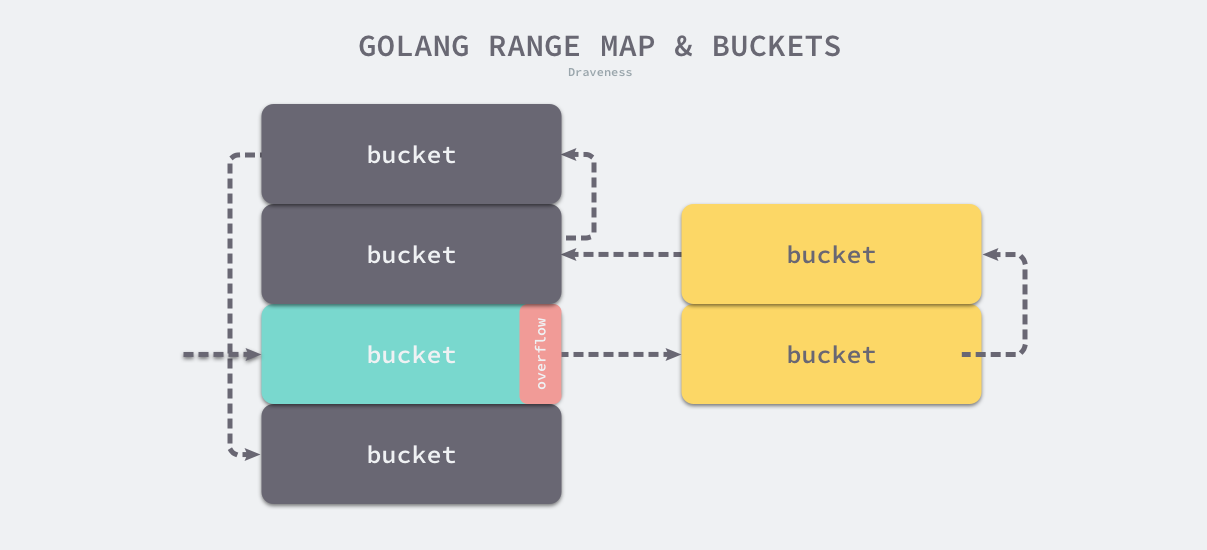
每个bmap都能存储8个键值对, 黄色部分是正常桶,绿色部分是溢出桶,溢出桶用extra存储溢出数据
桶的结构体定义
type bmap struct {
tophash [bucketCnt]uint8
}
编译期间他是这样的
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
初始化
Go中初始化hash表可以用字面量直接初始化
hash := map[string]int {
"1": 2,
"3": 4,
"5": 6,
}
使用make创建hash
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
// initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
// Find the size parameter B which will hold the requested # of elements.
// For hint < 0 overLoadFactor returns false since hint < bucketCnt.
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// allocate initial hash table
// if B == 0, the buckets field is allocated lazily later (in mapassign)
// If hint is large zeroing this memory could take a while.
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
都会进入这个步骤
- 计算哈希占用的内存是否溢出或者超出能分配的最大值;
- 调用
runtime.fastrand获取一个随机的哈希种子; - 根据传入的
hint计算出需要的最小需要的桶的数量; - 使用
runtime.makeBucketArray创建用于保存桶的数组;

如果桶数量小于2的4次方个,省略额外创建的过程
如果桶数量大于2的4次方个,额外创建2的B-4次方个
// bucketShift returns 1<<b, optimized for code generation.
func bucketShift(b uint8) uintptr {
// Masking the shift amount allows overflow checks to be elided.
return uintptr(1) << (b & (sys.PtrSize*8 - 1))
}
读写操作
读
以v := hash[key]访问的
// Replace m[k] with *map{access1,assign}(maptype, m, &k)
在编译期间会被替换成上述语句
- 当接受一个参数时,会使用
runtime.mapaccess1,该函数仅会返回一个指向目标值的指针;
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
return v
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
在 bucketloop 循环中,哈希会依次遍历正常桶和溢出桶中的数据,它会先比较哈希的高 8 位和桶中存储的 tophash,后比较传入的和桶中的值以加速数据的读写。用于选择桶序号的是哈希的最低几位,而用于加速访问的是哈希的高 8 位,这种设计能够减少同一个桶中有大量相等 tophash 的概率影响性能。
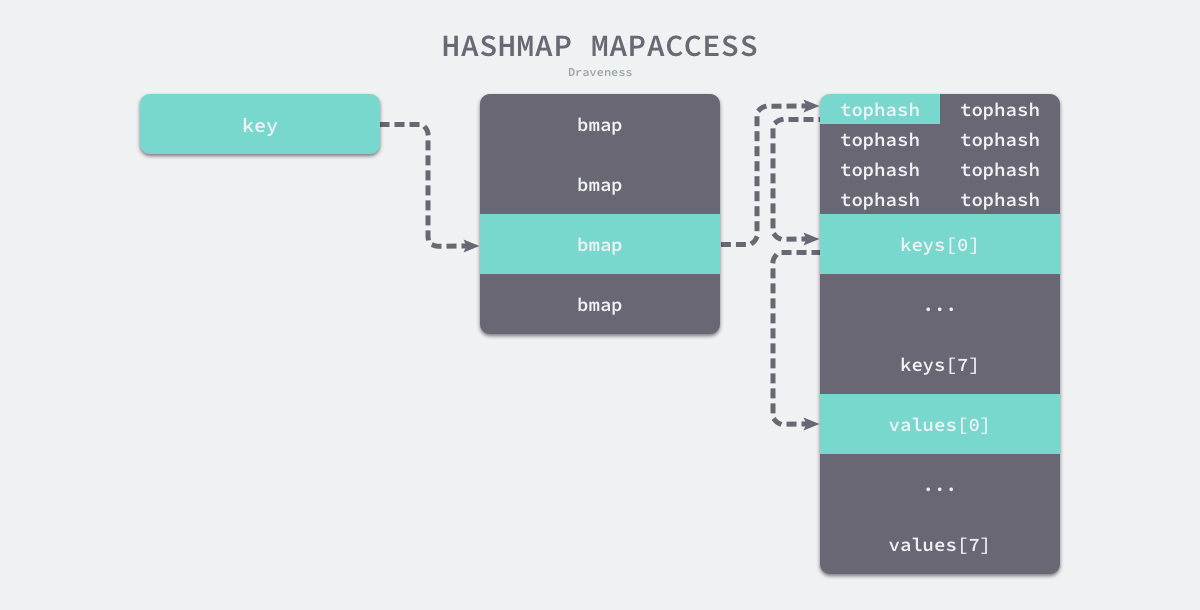
- 当接受两个参数时,会使用
runtime.mapaccess2,除了返回目标值之外,它还会返回一个用于表示当前键对应的值是否存在的bool值
每一个桶都是一整片的内存空间,当发现桶中的 tophash 与传入键的 tophash 匹配之后,我们会通过指针和偏移量获取哈希中存储的键 keys[0] 并与 key 比较,如果两者相同就会获取目标值的指针 values[0] 并返回
写
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
if raceenabled {
callerpc := getcallerpc()
pc := funcPC(mapassign)
racewritepc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled {
msanread(key, t.key.size)
}
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
hash := t.hasher(key, uintptr(h.hash0))
// Set hashWriting after calling t.hasher, since t.hasher may panic,
// in which case we have not actually done a write.
h.flags ^= hashWriting
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
top := tophash(hash)
var inserti *uint8
var insertk unsafe.Pointer
var elem unsafe.Pointer
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if !t.key.equal(key, k) {
continue
}
// already have a mapping for key. Update it.
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// Did not find mapping for key. Allocate new cell & add entry.
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
if inserti == nil {
// The current bucket and all the overflow buckets connected to it are full, allocate a new one.
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
// store new key/elem at insert position
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectelem() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(elem) = vmem
}
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
done:
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting
if t.indirectelem() {
elem = *((*unsafe.Pointer)(elem))
}
return elem
}
拆分一下
首先是一堆检测,下面是并发检测
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
然后计算hash值,hash0就是随机种子
hash := t.hasher(key, uintptr(h.hash0))
设置写入
h.flags ^= hashWriting
初始化桶
if h.buckets == nil {
h.buckets = newobject(t.bucket) // 初始化 1 个桶
}
定位桶并遍历
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
top := tophash(hash)
比较桶中存储的 tophash 和键的哈希,如果找到了相同结果就会返回目标位置的地址。其中 inserti 表示目标元素的在桶中的索引,insertk 和 val 分别表示键值对的地址,获得目标地址之后会通过算术计算寻址获得键值对 k 和 val
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if !t.key.equal(key, k) {
continue
}
// Update value
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
如果表满就扩容
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again
}
经典goto(
如果当前桶链溢出桶都满了的话,分配一个新的溢出桶
if inserti == nil {
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
更新数据
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
最后解锁写入标注
扩容
两种情况发生时触发哈希的扩容:
- 装载因子已经超过 6.5;
- 哈希使用了太多溢出桶;
根据触发的条件不同扩容的方式分成两种,如果这次扩容是溢出的桶太多导致的,那么这次扩容就是等量扩容
sameSizeGrow,sameSizeGrow是一种特殊情况下发生的扩容,当我们持续向哈希中插入数据并将它们全部删除时,如果哈希表中的数据量没有超过阈值,就会不断积累溢出桶造成缓慢的内存泄漏
扩容的入口是上文提到的hashGrow
func hashGrow(t *maptype, h *hmap) {
// If we've hit the load factor, get bigger.
// Otherwise, there are too many overflow buckets,
// so keep the same number of buckets and "grow" laterally.
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// commit the grow (atomic wrt gc)
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().
}
创建一组新桶和预创建的溢出桶,随后将原有的桶数组设置到 oldbuckets 上并将新的空桶设置到 buckets 上,溢出桶也使用了相同的逻辑更新
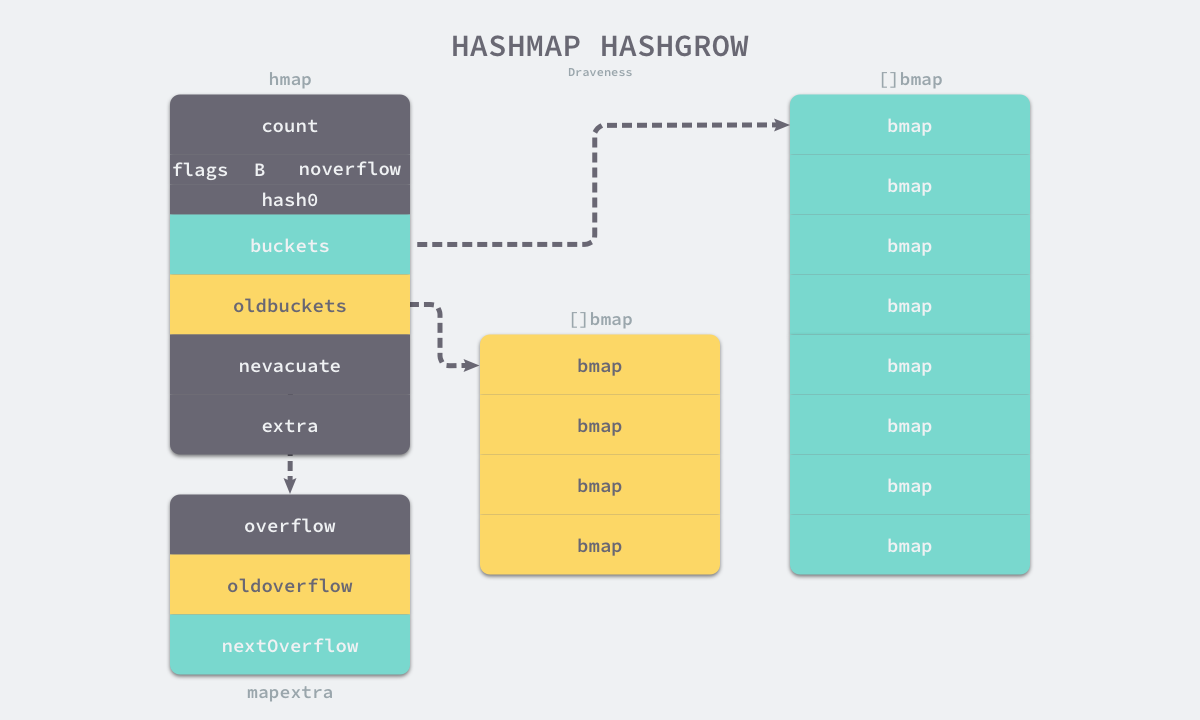
哈希表的迁移过程是在evacuate过程完成的,对传入桶中的元素进行再分配
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
newbit := h.noldbuckets()
if !evacuated(b) {
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.v = add(x.k, bucketCnt*uintptr(t.keysize))
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.v = add(y.k, bucketCnt*uintptr(t.keysize))
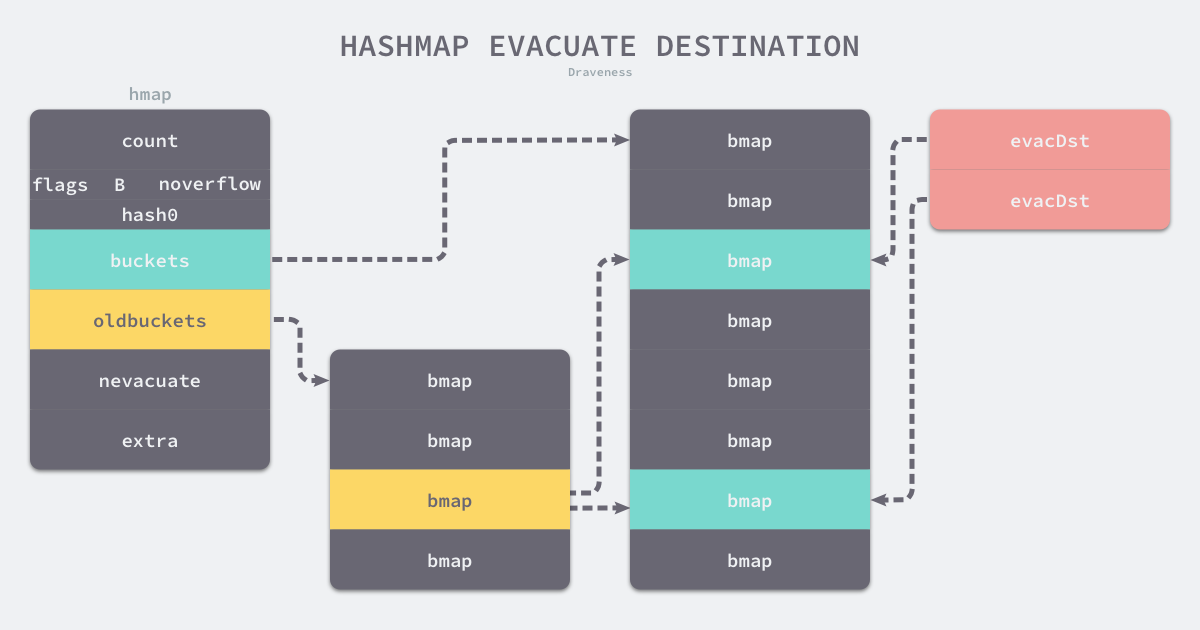
如果这是等量扩容,那么旧桶与新桶之间是一对一的关系,而当哈希表的容量翻倍时,每个旧桶的元素会都分流到新创建的两个桶中
删除
字符串
Go语言的字符串是一个只读的字节数组

如果是代码中存在的字符串,编译器会将其标记成只读数据 SRODATA
只读只意味着字符串会分配到只读的内存空间,但是 Go 语言只是不支持直接修改 string 类型变量的内存空间,我们仍然可以通过在 string 和 []byte 类型之间反复转换实现修改这一目的:
- 先将这段内存拷贝到堆或者栈上;
- 将变量的类型转换成
[]byte后并修改字节数据; - 将修改后的字节数组转换回
string;
字符串的数据结构是
type StringHeader struct {
Data uintptr
Len int
}
少了cap 自然也就不能扩容,只读设计
我们可以使用两种字面量方式在 Go 语言中声明字符串,即双引号和反引号
使用双引号声明的字符串和其他语言中的字符串没有太多的区别,它只能用于单行字符串的初始化,如果字符串内部出现双引号,需要使用 \ 符号避免编译器的解析错误,而反引号声明的字符串可以摆脱单行的限制
写json数据的时候,反引号显得特别方便

从代码中也能看出
标准字符串,即用引号定义的,不能出现换行,还需要用转义字符来escape双引号等
使用反引号的解析规则很简单,两个`之间的都是字符串内容
拼接
Go 语言拼接字符串会使用 + 符号,编译器会将该符号对应的 OADD 节点转换成 OADDSTR 类型的节点
- 如果小于或者等于 5 个,那么会调用
concatstring{2,3,4,5}等一系列函数; - 如果超过 5 个,那么会选择
runtime.concatstrings传入一个数组切片;
func concatstrings(buf *tmpBuf, a []string) string {
idx := 0
l := 0
count := 0
for i, x := range a {
n := len(x)
if n == 0 {
continue
}
l += n
count++
idx = i
}
if count == 0 {
return ""
}
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
return a[idx]
}
s, b := rawstringtmp(buf, l)
for _, x := range a {
copy(b, x)
b = b[len(x):]
}
return s
}
如果在栈上的话,生成的新字符串在堆上,确保返回不丢失
但是在正常情况下,运行时会调用 copy 将输入的多个字符串拷贝到目标字符串所在的内存空间。新的字符串是一片新的内存空间,与原来的字符串也没有任何关联,一旦需要拼接的字符串非常大,拷贝带来的性能损失是无法忽略的。
类型转换
func slicebytetostring(buf *tmpBuf, b []byte) (str string) {
l := len(b)
if l == 0 {
return ""
}
if l == 1 {
stringStructOf(&str).str = unsafe.Pointer(&staticbytes[b[0]])
stringStructOf(&str).len = 1
return
}
var p unsafe.Pointer
if buf != nil && len(b) <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(len(b)), nil, false)
}
stringStructOf(&str).str = p
stringStructOf(&str).len = len(b)
memmove(p, (*(*slice)(unsafe.Pointer(&b))).array, uintptr(len(b)))
return
}
byte to string
stringStructOf(&str).str = p
stringStructOf(&str).len = len(b)
memmove(p, (*(*slice)(unsafe.Pointer(&b))).array, uintptr(len(b)))
获取字符串指针,把内存地址p赋给str字段,设置字符串长度
memmove 是底层的内存复制函数,用于将 []byte 的数据复制到字符串的内存区域
将string转成byte也是一样的
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}
当传入缓冲区的时候,使用缓冲区存储[]byte
当没有传入缓冲区的时候,创建新的字节切片将字符串中的内容拷贝过去
语言基础
函数调用-作者分析
package main
func myFunction(a, b int) (int, int) {
return a + b, a - b
}
func main() {
myFunction(66, 77)
}
go tool compile -S -N -l main.go后得到
"".main STEXT size=68 args=0x0 locals=0x28
0x0000 00000 (main.go:7) MOVQ (TLS), CX
0x0009 00009 (main.go:7) CMPQ SP, 16(CX)
0x000d 00013 (main.go:7) JLS 61
0x000f 00015 (main.go:7) SUBQ $40, SP // 分配 40 字节栈空间
0x0013 00019 (main.go:7) MOVQ BP, 32(SP) // 将基址指针存储到栈上
0x0018 00024 (main.go:7) LEAQ 32(SP), BP
0x001d 00029 (main.go:8) MOVQ $66, (SP) // 第一个参数
0x0025 00037 (main.go:8) MOVQ $77, 8(SP) // 第二个参数
0x002e 00046 (main.go:8) CALL "".myFunction(SB)
0x0033 00051 (main.go:9) MOVQ 32(SP), BP
0x0038 00056 (main.go:9) ADDQ $40, SP
0x003c 00060 (main.go:9) RET

main 函数通过 SUBQ $40, SP 指令一共在栈上分配了 40 字节的内存空间:
| 空间 | 大小 | 作用 |
|---|---|---|
| SP+32 ~ BP | 8 字节 | main 函数的栈基址指针 |
| SP+16 ~ SP+32 | 16 字节 | 函数 myFunction 的两个返回值 |
| SP ~ SP+16 | 16 字节 | 函数 myFunction 的两个参数 |
当我们准备好函数的入参之后,会调用汇编指令 CALL "".myFunction(SB),这个指令首先会将 main 的返回地址存入栈中,然后改变当前的栈指针 SP 并执行 myFunction 的汇编指令
"".myFunction STEXT nosplit size=49 args=0x20 locals=0x0
0x0000 00000 (main.go:3) MOVQ $0, "".~r2+24(SP) // 初始化第一个返回值
0x0009 00009 (main.go:3) MOVQ $0, "".~r3+32(SP) // 初始化第二个返回值
0x0012 00018 (main.go:4) MOVQ "".a+8(SP), AX // AX = 66
0x0017 00023 (main.go:4) ADDQ "".b+16(SP), AX // AX = AX + 77 = 143
0x001c 00028 (main.go:4) MOVQ AX, "".~r2+24(SP) // (24)SP = AX = 143
0x0021 00033 (main.go:4) MOVQ "".a+8(SP), AX // AX = 66
0x0026 00038 (main.go:4) SUBQ "".b+16(SP), AX // AX = AX - 77 = -11
0x002b 00043 (main.go:4) MOVQ AX, "".~r3+32(SP) // (32)SP = AX = -11
0x0030 00048 (main.go:4) RET

在 myFunction 返回后,main 函数会通过以下的指令来恢复栈基址指针并销毁已经失去作用的 40 字节栈内存:
0x0033 00051 (main.go:9) MOVQ 32(SP), BP
0x0038 00056 (main.go:9) ADDQ $40, SP
0x003c 00060 (main.go:9) RET
通过分析 Go 语言编译后的汇编指令,我们发现 Go 语言使用栈传递参数和接收返回值,所以它只需要在栈上多分配一些内存就可以返回多个值
和c语言对比
C 语言和 Go 语言在设计函数的调用惯例时选择了不同的实现。C 语言同时使用寄存器和栈传递参数,使用 eax 寄存器传递返回值;而 Go 语言使用栈传递参数和返回值。我们可以对比一下这两种设计的优点和缺点:
- C 语言的方式能够极大地减少函数调用的额外开销,但是也增加了实现的复杂度;
- CPU 访问栈的开销比访问寄存器高几十倍3;
- 需要单独处理函数参数过多的情况;
- Go 语言的方式能够降低实现的复杂度并支持多返回值,但是牺牲了函数调用的性能;
- 不需要考虑超过寄存器数量的参数应该如何传递;
- 不需要考虑不同架构上的寄存器差异;
- 函数入参和出参的内存空间需要在栈上进行分配;
结构体在内存中是一片连续的空间,指向结构体的指针也是指向这个结构体的首地址
可以理解成数组的遍历,只不过成员变量的size不是都一样
本地版本分析
我查阅代码发现,go在1.17后已经修改成了寄存器传参优先,于是本地分析一下
方便起见,我直接在代码块里打注释了
main.myFunction STEXT nosplit size=64 args=0x10 locals=0x18 funcid=0x0 align=0x0 leaf
0x0000 00000 TEXT main.myFunction(SB), NOSPLIT|LEAF|ABIInternal, $32-16 // 声明函数 `main.myFunction` 的文本段;不允许栈分裂(NOSPLIT),是叶子函数。
0x0000 00000 MOVD.W R30, -32(RSP) // 保存调用者的链接寄存器(R30)到栈上,便于函数返回时恢复。
0x0004 00004 MOVD R29, -8(RSP) // 保存调用者的帧指针(R29)到栈上,便于函数返回时恢复。
0x0008 00008 SUB $8, RSP, R29 // 分配栈空间并更新帧指针 R29。
0x000c 00012 FUNCDATA $0, gclocals·g2BeySu+wFnoycgXfElmcg==(SB) // 调试信息:局部变量的垃圾回收元数据。
0x000c 00012 FUNCDATA $1, gclocals·g2BeySu+wFnoycgXfElmcg==(SB) // 调试信息:堆分配信息。
0x000c 00012 FUNCDATA $5, main.myFunction.arginfo1(SB) // 调试信息:函数参数信息。
0x000c 00012 MOVD R0, main.a(FP) // 将参数 `a` 从寄存器 R0 保存到栈帧(FP 表示帧指针)。
0x0010 00016 MOVD R1, main.b+8(FP) // 将参数 `b` 从寄存器 R1 保存到栈帧。
0x0014 00020 MOVD ZR, main.~r0-8(SP) // 初始化返回值 1(~r0)为 0,存储在栈帧的相应位置。
0x0018 00024 MOVD ZR, main.~r1-16(SP) // 初始化返回值 2(~r1)为 0,存储在栈帧的相应位置。
0x001c 00028 ADD R1, R0, R0 // 计算 `a + b`,结果存储在 R0(第一个返回值)。
0x0020 00032 MOVD R0, main.~r0-8(SP) // 将第一个返回值写入栈帧的位置。
0x0024 00036 MOVD main.a(FP), R2 // 从栈帧中加载参数 `a` 到寄存器 R2。
0x0028 00040 SUB R1, R2, R1 // 计算 `a - b`,结果存储在 R1(第二个返回值)。
0x002c 00044 MOVD R1, main.~r1-16(SP) // 将第二个返回值写入栈帧的位置。
0x0030 00048 ADD $24, RSP, R29 // 恢复帧指针 R29。
0x0034 00052 ADD $32, RSP // 回收栈空间。
0x0038 00056 RET (R30) // 从链接寄存器 R30 返回。
main.main STEXT size=64 args=0x0 locals=0x18 funcid=0x0 align=0x0
0x0000 00000 TEXT main.main(SB), ABIInternal, $32-0 // 声明函数 `main.main` 的文本段;栈大小为 32 字节。
0x0000 00000 MOVD 16(g), R16 // 检查 Goroutine 的栈指针是否有足够空间。
0x0004 00004 PCDATA $0, $-2 // 调试信息:PC 数据。
0x0004 00004 CMP R16, RSP // 比较栈指针是否足够。
0x0008 00008 BLS 48 // 如果栈空间不足,跳转到扩展栈的逻辑。
0x000c 00012 PCDATA $0, $-1 // 调试信息:PC 数据。
0x000c 00012 MOVD.W R30, -32(RSP) // 保存链接寄存器 R30 到栈上。
0x0010 00016 MOVD R29, -8(RSP) // 保存帧指针 R29 到栈上。
0x0014 00020 SUB $8, RSP, R29 // 分配栈空间并更新帧指针 R29。
0x0018 00024 FUNCDATA $0, gclocals·g2BeySu+wFnoycgXfElmcg==(SB) // 调试信息:局部变量的垃圾回收元数据。
0x0018 00024 FUNCDATA $1, gclocals·g2BeySu+wFnoycgXfElmcg==(SB) // 调试信息:堆分配信息。
0x0018 00024 MOVD $66, R0 // 将常量 `66` 作为第一个参数存入寄存器 R0。
0x001c 00028 MOVD $77, R1 // 将常量 `77` 作为第二个参数存入寄存器 R1。
0x0020 00032 PCDATA $1, $0 // 调试信息:PC 数据。
0x0020 00032 CALL main.myFunction(SB) // 调用函数 `main.myFunction`。
0x0024 00036 LDP -8(RSP), (R29, R30) // 从栈帧中加载返回值到寄存器 R29 和 R30。
0x0028 00040 ADD $32, RSP // 回收栈空间。
0x002c 00044 RET (R30) // 从链接寄存器 R30 返回。
好吧,这么简单一个程序,看了半天还半知半解,留个坑,以后学懂汇编再来补
接口
Go 语言中的接口是一组方法的签名,它是 Go 语言的重要组成部分
Go的一个接口如下
type error interface {
Error() string
}
只能定义方法签名,不能像java一样含有成员变量
如果一个类型要实现接口,就只需要实现定义的这个方法签名就行了,实现接口的所有方法就隐式地实现了接口
我们使用上述 RPCError 结构体时并不关心它实现了哪些接口,Go 语言只会在传递参数、返回参数以及变量赋值时才会对某个类型是否实现接口进行检查
func main() {
var rpcErr error = NewRPCError(400, "unknown err") // typecheck1
err := AsErr(rpcErr) // typecheck2
println(err)
}
func NewRPCError(code int64, msg string) error {
return &RPCError{ // typecheck3
Code: code,
Message: msg,
}
}
func AsErr(err error) error {
return err
}
编译期间触发三次类型检查
- 将
*RPCError类型的变量赋值给error类型的变量rpcErr; - 将
*RPCError类型的变量rpcErr传递给签名中参数类型为error的AsErr函数; - 将
*RPCError类型的变量从函数签名的返回值类型为error的NewRPCError函数中返回;
两种接口
Go使用iface表示第一种接口,使用eface表示不带任何方法的接口interface
需要注意的是,与 C 语言中的 void * 不同,interface{} 类型不是任意类型
type Duck interface { ... }
type Cat struct{}
func (c Cat) Quack() {
fmt.Println("Cat says: Quack!")
}
func main() {
var d Duck
d = Cat{} // 值类型赋值,直接实现了接口
d = &Cat{} // 指针类型赋值,编译器会自动解引用
}
type Cat struct{}
func (c *Cat) Quack() {
fmt.Println("Cat says: Quack!")
}
func main() {
var d Duck
// d = Cat{} // 编译错误,值类型无法调用指针接收器方法
d = &Cat{} // 指针类型赋值,可以调用指针接收器方法
}
| 结构体实现接口 | 结构体指针实现接口 |
|---|---|
| 结构体初始化变量 | 通过 |
| 结构体指针初始化变量 | 通过 |
go语言在传参的时候是传值的
无论上述代码中初始化的变量 c 是 Cat{} 还是 &Cat{},使用 c.Quack() 调用方法时都会发生值拷贝
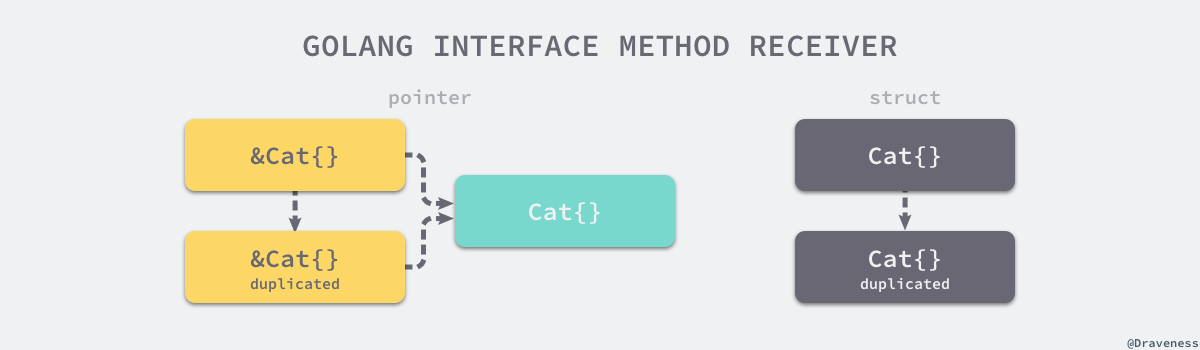
- 如上图左侧,对于
&Cat{}来说,这意味着拷贝一个新的&Cat{}指针,这个指针与原来的指针指向一个相同并且唯一的结构体,所以编译器可以隐式的对变量解引用(dereference)获取指针指向的结构体; - 如上图右侧,对于
Cat{}来说,这意味着Quack方法会接受一个全新的Cat{},因为方法的参数是*Cat,编译器不会无中生有创建一个新的指针;即使编译器可以创建新指针,这个指针指向的也不是最初调用该方法的结构体;
package main
type TestStruct struct{}
func NilOrNot(v interface{}) bool {
return v == nil
}
func main() {
var s *TestStruct
fmt.Println(s == nil) // #=> true
fmt.Println(NilOrNot(s)) // #=> false
}
$ go run main.go
true
false
在调用 NilOrNot(s) 时:
- 变量 s 是
*TestStruct类型的变量,且值为 nil。 - 将 s 赋值给 v interface{} 时
- 接口的动态类型为
*TestStruct。 - 接口的动态值为 nil。
- 接口的动态类型为
执行 v == nil考虑接口的动态类型是否为 nil和接口的动态值是否为 nil
v的动态类型已经为那个结构体了,所以返回false
if t, ok := v.(*TestStruct); ok {
fmt.Println(t == nil)
}
如果使用类型断言,那么就能判断他存储的值是不是nil了
eface
type eface struct { // 16 字节
_type *_type
data unsafe.Pointer
}
只包含指向底层数据和类型的两个指针,因为任何类型都能转换成它
type字段如下
type _type struct {
size uintptr
ptrdata uintptr
hash uint32
tflag tflag
align uint8
fieldAlign uint8
kind uint8
equal func(unsafe.Pointer, unsafe.Pointer) bool
gcdata *byte
str nameOff
ptrToThis typeOff
}
size字段存储了类型占用的内存空间,为内存空间的分配提供信息;hash字段能够帮助我们快速确定类型是否相等;equal字段用于判断当前类型的多个对象是否相等,该字段是为了减少 Go 语言二进制包大小从typeAlg结构体中迁移过来的
iface
type iface struct { // 16 字节
tab *itab
data unsafe.Pointer
}
type itab struct { // 32 字节
inter *interfacetype
_type *_type
hash uint32
_ [4]byte
fun [1]uintptr
}
除了接口类型外,还有具体类型
反射
reflect.Typeof //获取类型信息
reflect.ValueOf //获取数据的运行时表示
三大法则
- 从
interface{}变量可以反射出反射对象; - 从反射对象可以获取
interface{}变量; - 要修改反射对象,其值必须可设置;
类型和值
type emptyInterface struct {
typ *rtype
word unsafe.Pointer
}
获取变量类型的函数将传入的变量隐式转换成emptyInterface并返回typ
func TypeOf(i interface{}) Type {
eface := *(*emptyInterface)(unsafe.Pointer(&i))
return toType(eface.typ)
}
func toType(t *rtype) Type {
if t == nil {
return nil
}
return t
}
reflect.rtype 是一个实现了 reflect.Type 接口的结构体,他的String方法返回类型名称
func (t *rtype) String() string {
s := t.nameOff(t.str).name()
if t.tflag&tflagExtraStar != 0 {
return s[1:]
}
return s
}
ValueOf的实现也很简单
func ValueOf(i interface{}) Value {
if i == nil {
return Value{}
}
escapes(i)
return unpackEface(i)
}
func unpackEface(i interface{}) Value {
e := (*emptyInterface)(unsafe.Pointer(&i))
t := e.typ
if t == nil {
return Value{}
}
f := flag(t.Kind())
if ifaceIndir(t) {
f |= flagIndir
}
return Value{t, e.word, f}
}
unpackEface把传入的接口转换类型后,把对应字段包装成结构体返回
更新变量
更新变量的Value的时候,我们要使用Set方法
func (v Value) Set(x Value) {
v.mustBeAssignable()
x.mustBeExported()
var target unsafe.Pointer
if v.kind() == Interface {
target = v.ptr
}
x = x.assignTo("reflect.Set", v.typ, target)
typedmemmove(v.typ, v.ptr, x.ptr)
}
值必须是可寻址的,值必须是可导出的(首字母大写),值不是常亮
如果当前值和目标类型可以直接兼容,assignTo 会直接返回一个新的 reflect.Value
如果目标类型是接口,而当前值实现了这个接口,则 assignTo 会将当前值包装成接口类型
实现协议
Implements方法可以判断某些类型是否遵循特定的接口
func (t *rtype) Implements(u Type) bool {
if u == nil {
panic("reflect: nil type passed to Type.Implements")
}
if u.Kind() != Interface {
panic("reflect: non-interface type passed to Type.Implements")
}
return implements(u.(*rtype), t)
}
又调用implements方法检查传入的类型是不是接口,如果不是接口或者空就直接返回
func implements(T, V *rtype) bool {
if T.Kind() != Interface {
return false
}
t := (*interfaceType)(unsafe.Pointer(T))
if len(t.methods) == 0 {
return true
}
...
v := V.uncommon()
if v == nil {
return false
}
i := 0
vmethods := v.methods()
for j := 0; j < int(v.mcount); j++ {
tm := &t.methods[i]
tmName := t.nameOff(tm.name)
vm := vmethods[j]
vmName := V.nameOff(vm.name)
if vmName.name() == tmName.name() && V.typeOff(vm.mtyp) == t.typeOff(tm.typ) {
if !tmName.isExported() {
tmPkgPath := tmName.pkgPath()
if tmPkgPath == "" {
tmPkgPath = t.pkgPath.name()
}
vmPkgPath := vmName.pkgPath()
if vmPkgPath == "" {
vmPkgPath = V.nameOff(v.pkgPath).name()
}
if tmPkgPath != vmPkgPath {
continue
}
}
if i++; i >= len(t.methods) {
return true
}
}
}
return false
}
如果接口中不包含任何方法,就意味着这是一个空的接口,任意类型都自动实现该接口,这时会直接返回 true
由于方法都是按照字母序存储的,所以遍历接口只需要n次比较
核心就是双指针遍历
还可以动态调用函数
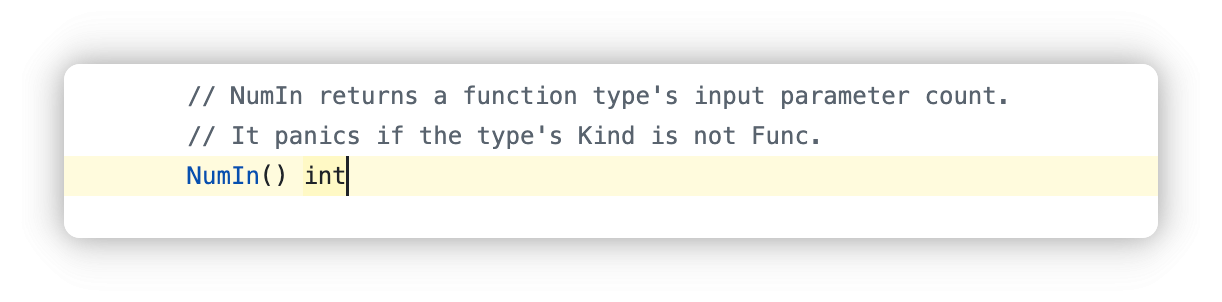
NumIn记录了参数个数
v := reflect.ValueOf(Add)
反射获取函数Value
然后得到参数列表
argv := make([]reflect.Value, t.NumIn())
传入reflect.Value类型的参数
然后使用v.Call(argv)调用函数
func (v Value) Call(in []Value) []Value {
v.mustBe(Func)
v.mustBeExported()
return v.call("Call", in)
}
Call的实现方法如上
也是检查,必须是函数且可导出
步进call方法,我们开始查看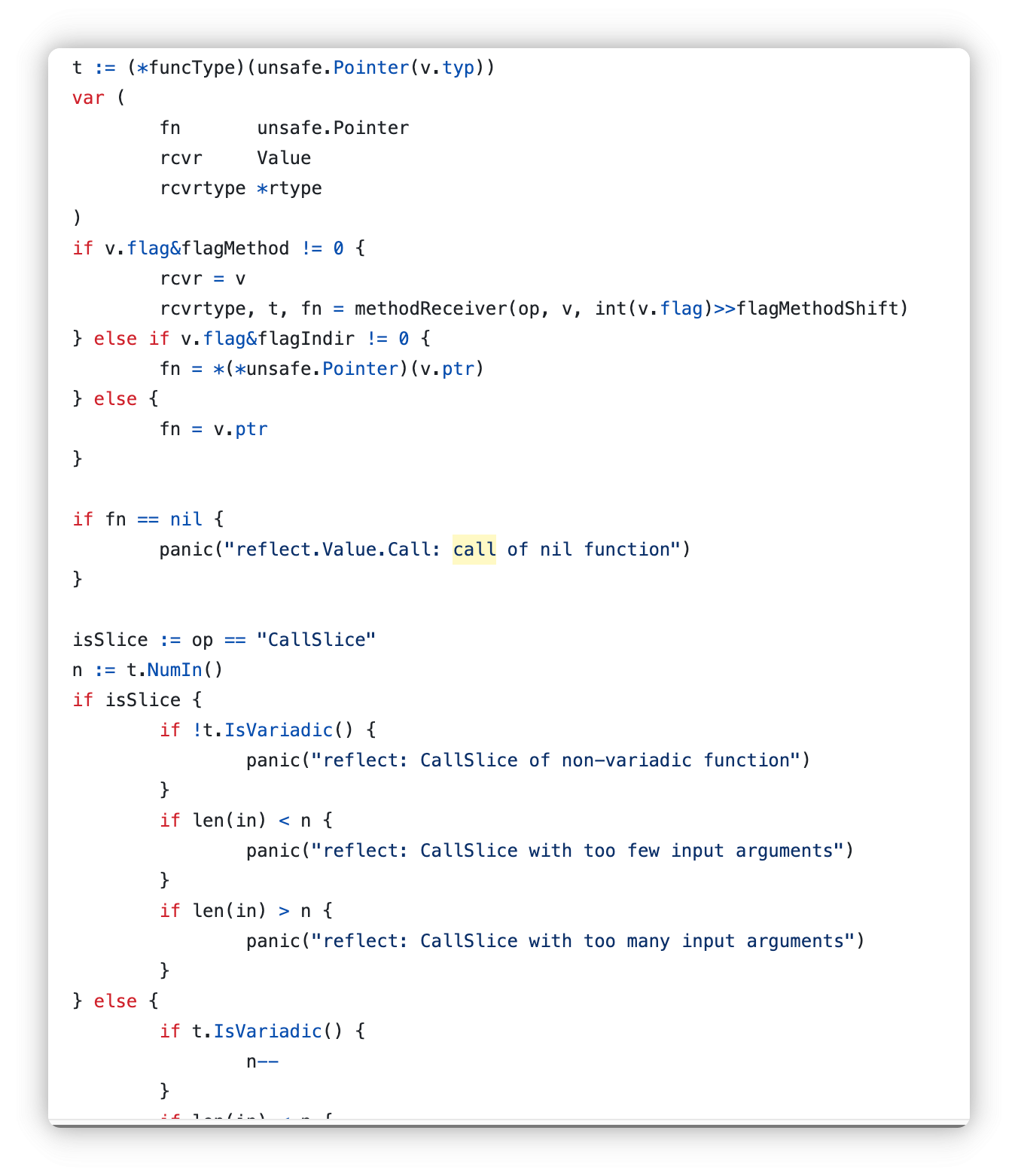
首先进行参数检查和类型检查
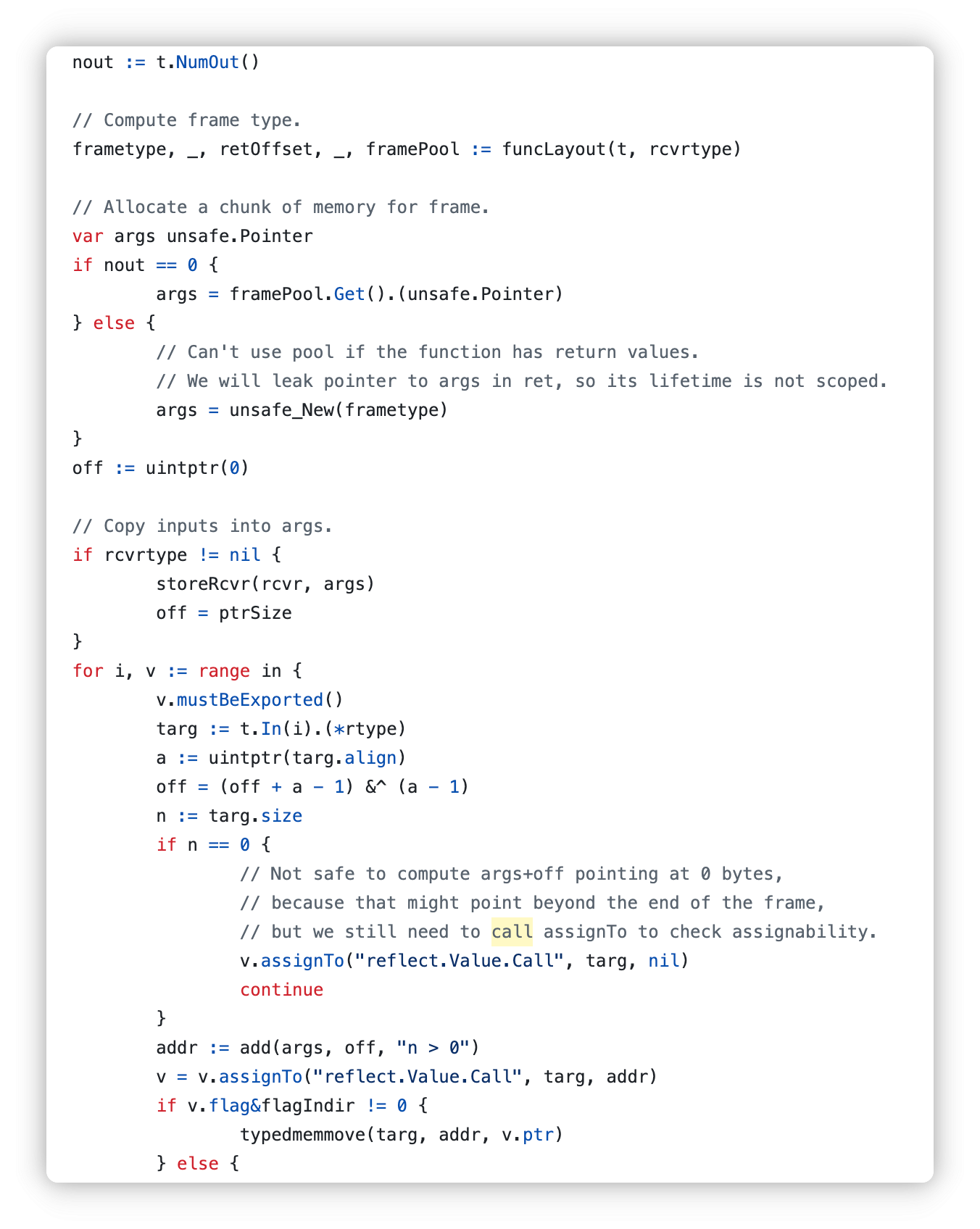
之后是参数的入栈
call(frametype, fn, args, uint32(frametype.size), uint32(retOffset))
调用函数
// For testing; see TestCallMethodJump.
if callGC {
runtime.GC()
}
var ret []Value
if nout == 0 {
typedmemclr(frametype, args)
framePool.Put(args)
} else {
// Zero the now unused input area of args,
// because the Values returned by this function contain pointers to the args object,
// and will thus keep the args object alive indefinitely.
typedmemclrpartial(frametype, args, 0, retOffset)
// Wrap Values around return values in args.
ret = make([]Value, nout)
off = retOffset
for i := 0; i < nout; i++ {
tv := t.Out(i)
a := uintptr(tv.Align())
off = (off + a - 1) &^ (a - 1)
if tv.Size() != 0 {
fl := flagIndir | flag(tv.Kind())
ret[i] = Value{tv.common(), add(args, off, "tv.Size() != 0"), fl}
// Note: this does introduce false sharing between results -
// if any result is live, they are all live.
// (And the space for the args is live as well, but as we've
// cleared that space it isn't as big a deal.)
} else {
// For zero-sized return value, args+off may point to the next object.
// In this case, return the zero value instead.
ret[i] = Zero(tv)
}
off += tv.Size()
}
}
return ret
}
如果没有返回值,直接清空栈,将栈帧归还到内存池,以便减少后续调用开销
有返回值的话,只清空调用帧中未被返回值占用的部分
ret = make([]Value, nout)
分配切片,在for循环中遍历封装为reflect.Value返回ret切片
常用关键字
for和range
package main
import (
"fmt"
)
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for _, v := range arr {
newArr = append(newArr, &v)
}
for _, v := range newArr {
fmt.Println(&v)
fmt.Println(*v)
}
}
猜猜结果是什么 1 2 3? 还是 3 3 3?
其实严格意义来说都对,也都不对
在go的早期版本,v的地址都一样,三个变量的值都是3
但是在我使用的go1.23.3 输出结果是 1 2 3 ,说明go编译器已经对range内v的内存地址有了更改
这个特性是在go1.22的更新,同时也支持了对整形数据的range
另外对于map的range,并不是按照严格的顺序,所以不要指望range遍历map的时候是按顺序遍历的
经典循环
for Ninit; Left; Right {
NBody
}
初始值,继续条件和结束条件
这个节点在编译器看来是一个OFOR类型的节点
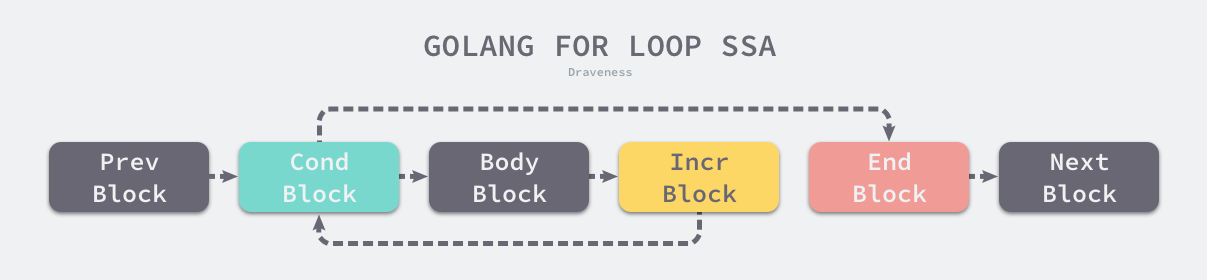
一个常见的for循环会被转化为这种控制结构
范围循环
即 for range

- 分析遍历数组和切片清空元素的情况;
- 分析使用
for range a {}遍历数组和切片,不关心索引和数据的情况; - 分析使用
for i := range a {}遍历数组和切片,只关心索引的情况; - 分析使用
for i, elem := range a {}遍历数组和切片,关心索引和数据的情况;
对于所有的 range 循环,Go 语言都会在编译期将原切片或者数组赋值给一个新变量 ha,在赋值的过程中就发生了拷贝,而我们又通过 len 关键字预先获取了切片的长度,所以在循环中追加新的元素也不会改变循环执行的次数
遍历hash表
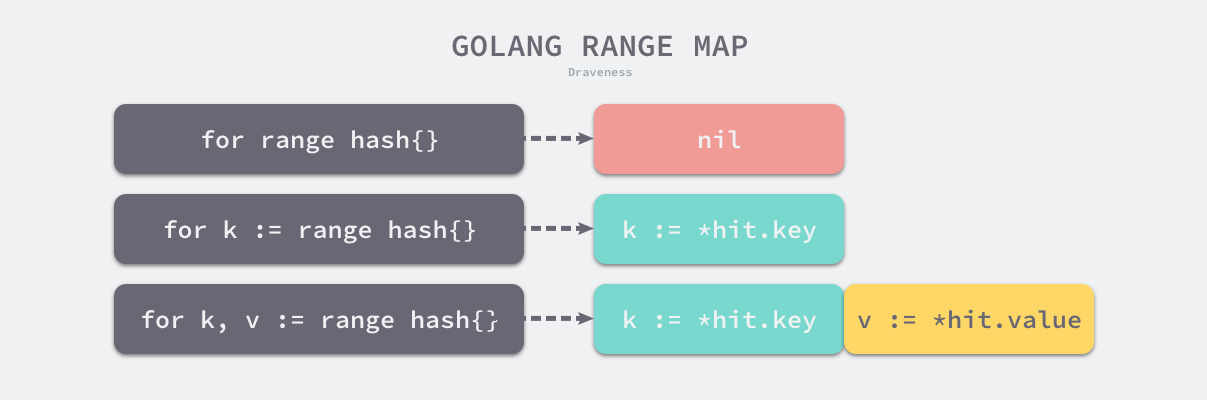
首先会选出一个绿色的正常桶开始遍历,随后遍历所有黄色的溢出桶,最后依次按照索引顺序遍历哈希表中其他的桶,直到所有的桶都被遍历完成
Select
select是操作系统中的系统调用 我们经常会使用 select、poll 和 epoll 等函数构建 I/O 多路复用模型提升程序的性能
C 语言的 select 系统调用可以同时监听多个文件描述符的可读或者可写的状态,Go 语言中的 select 也能够让 Goroutine 同时等待多个 Channel 可读或者可写,在多个文件或者 Channel状态改变之前,select 会一直阻塞当前线程或者 Goroutine
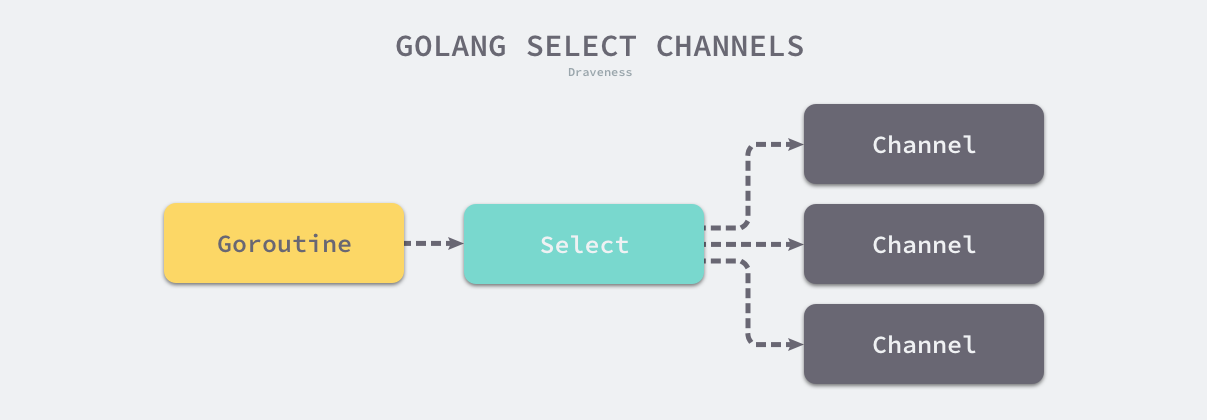
select 是与 switch 相似的控制结构,与 switch 不同的是,select 中虽然也有多个 case,但是这些 case 中的表达式必须都是 Channel 的收发操作。下面的代码就展示了一个包含 Channel 收发操作的 select 结构
func fibonacci(c, quit chan int) {
x, y := 0, 1
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
}
两个现象
select 能在 Channel 上进行非阻塞的收发操作
select 在遇到多个 Channel 同时响应时,会随机执行一种情况
非阻塞的收发
在通常情况下,select 语句会阻塞当前 Goroutine 并等待多个 Channel 中的一个达到可以收发的状态。但是如果 select 控制结构中包含 default 语句,那么这个 select 语句在执行时会遇到以下两种情况:
- 当存在可以收发的 Channel 时,直接处理该 Channel 对应的
case; - 当不存在可以收发的 Channel 时,执行
default中的语句;
实现原理
select 在 Go 语言的源代码中不存在对应的结构体,但是我们使用 runtime.scase结构体表示 select 控制结构中的 case:
type scase struct {
c *hchan // chan
elem unsafe.Pointer // data element
}
select 语句在编译期间会被转换成 OSELECT 节点。每个 OSELECT 节点都会持有一组 OCASE 节点,如果 OCASE 的执行条件是空,那就意味着这是一个 default 节点
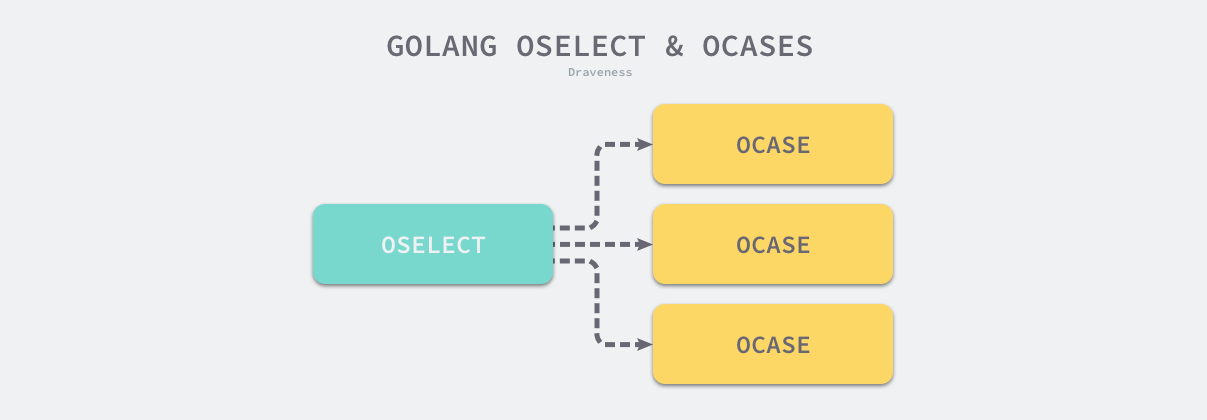
每一个 OCASE 既包含执行条件也包含满足条件后执行的代码
select不存在任何的case;select只存在一个case;select存在两个case,其中一个case是default;select存在多个case;
上述四种情况不仅会涉及编译器的重写和优化,还会涉及 Go 语言的运行时机制,我们会从编译期间和运行时两个角度分析上述情况。
不存在case
if n == 0 {
return []*Node{mkcall("block", nil, nil)}
}
直接阻塞
一个case
if ch == nil {
block()
}
v, ok := <-ch
当 case 中的 Channel 是空指针时,会直接挂起当前 Goroutine 并陷入永久休眠
两个case,并且其中一个是default
Go 语言的编译器就会认为这是一次非阻塞的收发操作
在不存在接收方或者缓冲区空间不足时,当前 Goroutine 都不会阻塞而是会直接返回
三个case

代码比较多,selectgo我们分段分析
func selectgo(cas0 *scase, order0 *uint16, pc0 *uintptr, nsends, nrecvs int, block bool) (int, bool)
函数签名部分
cas0: 指向scase数组的指针,scase表示通道的操作(发送或接受)
order0:指向存储选择顺序的数组指针
pc0:记录调试用的程序计数器
nsends和nrecvs:分别表示发送和接受的操作数量
block: 是否阻塞等待
cas1 := (*[1 << 16]scase)(unsafe.Pointer(cas0))
order1 := (*[1 << 17]uint16)(unsafe.Pointer(order0))
首先把这两个转换为固定大小的指针数组
ncases := nsends + nrecvs
scases := cas1[:ncases:ncases]
pollorder := order1[:ncases:ncases] // 记录随机顺序
lockorder := order1[ncases:][:ncases:ncases] // 记录锁定顺序
计算总case
for i := range scases {
if cas.c == nil {
cas.elem = nil // 允许 GC
continue
}
j := fastrandn(uint32(norder + 1))
pollorder[norder] = pollorder[j]
pollorder[j] = uint16(i)
norder++
}
随机打乱,避免饥饿问题
for i := range lockorder {
j := i
c := scases[pollorder[i]].c
for j > 0 && scases[lockorder[(j-1)/2]].c.sortkey() < c.sortkey() {
k := (j - 1) / 2
lockorder[j] = lockorder[k]
j = k
}
lockorder[j] = pollorder[i]
}
通道锁
for _, casei := range pollorder {
cas := &scases[casei]
c := cas.c
if casi >= nsends {
// 接收操作
if sg := c.sendq.dequeue(); sg != nil {
goto recv // 有等待的发送者,立即执行接收
}
if c.qcount > 0 {
goto bufrecv // 有缓冲数据,直接接收
}
if c.closed != 0 {
goto rclose // 通道关闭
}
} else {
// 发送操作
if c.closed != 0 {
goto sclose // 通道关闭
}
if sg := c.recvq.dequeue(); sg != nil {
goto send // 有等待的接收者,立即执行发送
}
if c.qcount < c.dataqsiz {
goto bufsend // 缓冲未满,直接发送
}
}
}
遍历case,在非阻塞的时候立刻返回
在阻塞的时候
gp = getg()
nextp = &gp.waiting
for _, casei := range lockorder {
sg := acquireSudog()
sg.g = gp
sg.isSelect = true
sg.elem = cas.elem
sg.c = c
*nextp = sg
nextp = &sg.waitlink
if casi < nsends {
c.sendq.enqueue(sg)
} else {
c.recvq.enqueue(sg)
}
}
把等待信息 sudog加入通道队列
等待被唤醒
sg = (*sudog)(gp.param)
for sg1 := gp.waiting; sg1 != nil; sg1 = sg1.waitlink {
sg1.isSelect = false
sg1.elem = nil
sg1.c = nil
}
被唤醒了之后清理等待队列,返回成功的case
defer
之前已经了解过,defer用于在函数调用结束后的一些操作,比如数据库回滚之类的
我们在 Go 语言中使用 defer 时会遇到两个常见问题,这里会介绍具体的场景并分析这两个现象背后的设计原理:
defer关键字的调用时机以及多次调用defer时执行顺序是如何确定的;defer关键字使用传值的方式传递参数时会进行预计算,导致不符合预期的结果;
作用域
func main() {
for i := 0; i < 5; i++ {
defer fmt.Println(i)
}
}
defer 并不会延迟表达式的计算,而是延迟函数调用的执行
func main() {
startedAt := time.Now()
defer fmt.Println(time.Since(startedAt))
time.Sleep(time.Second)
}
对于这样的函数
打印出来接近0s,因为在到defer定义的时候,后面的就已经计算出结果并赋值了
把这个简单的语句改成匿名函数的话,就可以计算出正常的值了,因为defer此时捕获的不再是立刻求值的结果,而是整个匿名函数的引用 匿名函数的实际执行是在函数退出时发生
数据结构
type _defer struct {
siz int32
started bool
openDefer bool
sp uintptr
pc uintptr
fn *funcval
_panic *_panic
link *_defer
}
runtime._defer 结构体是延迟调用链表上的一个元素,所有的结构体都会通过 link 字段串联成链表。

堆分配、栈分配和开放编码是处理 defer 关键字的三种方法